Notes for SEC
Contents
This is my notes for Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation.
- arxiv: https://arxiv.org/abs/1603.06098
- github: https://github.com/kolesman/SEC
Introduction
本篇论文主要是介绍了针对 image-level 弱监督语义分割的一种新的 loss function。这个 loss function 由三部分组成:
- seeding loss:针对使用 Image calssification CNN 来进行 object localization 的问题。传统的分类网络(比如 AlexNet 或者说 VGG)能够生成可靠的定位线索(即 seeds ),然是在预测物体确切的空间范围上就不怎么样了。这个 seeding loss 主要就是来使得分割网络能够准确地匹配到物体的定位线索(localization cues),但是不要扩展得太开,基本上就是只标出物体的中心位置,而无视图像中的其他不相关的部分。
- expansion loss:因为是要用 image-level 的标注来训练份额网络,所以需要考虑用 global pooling 来将预测出的 mask 转换成 image-level label scrores。这个 pooling 层的选择很大程度上决定了最终训练得到的分割网络的预测质量。一般来说,global max-pooling 倾向于低估物体的尺寸,而global average-pooling 则倾向于高估。本文使用了一种叫做 global weighted rank pooling 的方法来将物体的 seeds 扩展到一个尺寸比较合适的区域来计分,从而计算 expansion loss。这种方法是 max-pooling 和 average-pooling 的一种泛化版本,并且性能比这两者要高。
- constrain-to-boundary loss:根据 image-level label 训练出来的网络很少能够捕捉到图像中物体的精确边缘,而且仅仅在测试的时候在网络后面套一层全连接的 CRF 也往往难以完全克服这个缺陷。这是因为按照传统方法训练出来的网络,即便是对于未标记的区域,也倾向于有比较高的置信度。于是本文提出了一种新的 loss, 能够使得网络在训练的时候就减轻不精确的边缘预测。这一 loss 主要是对预测得到的 mask 进行约束,使其能在一定程度上遵循低层次的图像信息,特别是物体的边缘这样的重要信息。
文中将这一方法称为SEC,即 Seed,Expand和Constrain。之后将分块介绍其具体实现。
Related Work
现有的 image-level 弱监督语义分割的方法主要可以分为三类:
- 基于图的方法(graph-based Model):根据图像内或图像间的部分(segments)或是超像素(superpixels)的相似性来推断其标签。
- 多实例学习(multiple instance learning):使用 per-image loss function 来进行训练,本质上是保持了图像中能够被用来生成 mask 的一种空间表示。
- 例如 MIL-FCN 以及 MIL-ILP,其区别主要在于 pooling 策略,也就是说它们如何将其内在的空间表示转换到 per-image labels。
- 自学习(self-training):模型本身使用基于 EM-like 的方法来生成 pixel-level 的标注,然后再来训练 fully-supervised 的分割网络。
- 例如 EM-Adapt 以及 CCNN,其区别在于如何将 per-image annotation 转换到 mask 并保持其一致性。
- SN_B 又增加了额外的步骤来创建于合并多个目标的proposal。
文中介绍的 SEC 包含了后两类方法,即其既使用了 per-image 的 loss,也使用了 per-pixel 的 loss 形式。
Weakly supervised segmentation from image-level labels
Table of Symbols
| Symbol | Description | Note |
|---|---|---|
| $\chi$ | the space of images | |
| $X_i$ | an image | $X_i \in \chi$ |
| $N$ | number of images | |
| $Y$ | a segmentation mask | $Y = (y_1 \dots y_n)$ |
| $y_i$ | a semantic label at $i$ spatial location | |
| $n$ | number of spatial locations | |
| $u$ | a location | $u\in {1,2,\dots n}$ |
| $C$ | a set of all labels | $C=C’ \cup {c^{bg}}$, size is $k$ |
| $C’$ | a set of all foreground labels | |
| $c^{bg}$ | a background label | |
| $k$ | number of kinds of labels | |
| $c$ | a label | $c\in C$ |
| $T_i$ | a set of weakly annotated foreground labels in an image | $T_i \in C’$ |
| $S_c$ | a set of locations that are labeled with class $c$ by the weak localizatio procdure | |
| $f(X;\theta)$ | segment network, briefly written as $f(X)$ | $f_{u,c}(X;\theta)=p(y_u=c \mid X)$ |
The SEC loss for weakly supervised image segmentation
本节将介绍 SEC 的 loss function 的三个组成部分,其各自的功用如下:
- $L_{seed}$: 为网络预测提供提示(hint)
- $L_{expand}$: 惩罚太小或者是搞错对象的预测 mask
- $L_{constrain}$: 鼓励分割能够与图像空间以及色彩结构相适应
本文的目标是训练一个参数为$\theta$的一个深度卷积神经网络$f(X;\theta)$,其能够预测在任一位置$u\in {1,2, \dots , n}$上任一标签$c\in C$的条件概率,也就是说,$f_{u,c}(X;\theta)=p(y_u=c \mid X)$。
该网络的训练即为下式的优化问题: $$ min_{\theta} \sum_{(X,T)\in D}[L_{seed}(f(X;\theta), T) + L_{expand}(f(X;\theta), T) + L_{constrain}(X, f(X;\theta))] $$
整个网络的结构如下图所示:
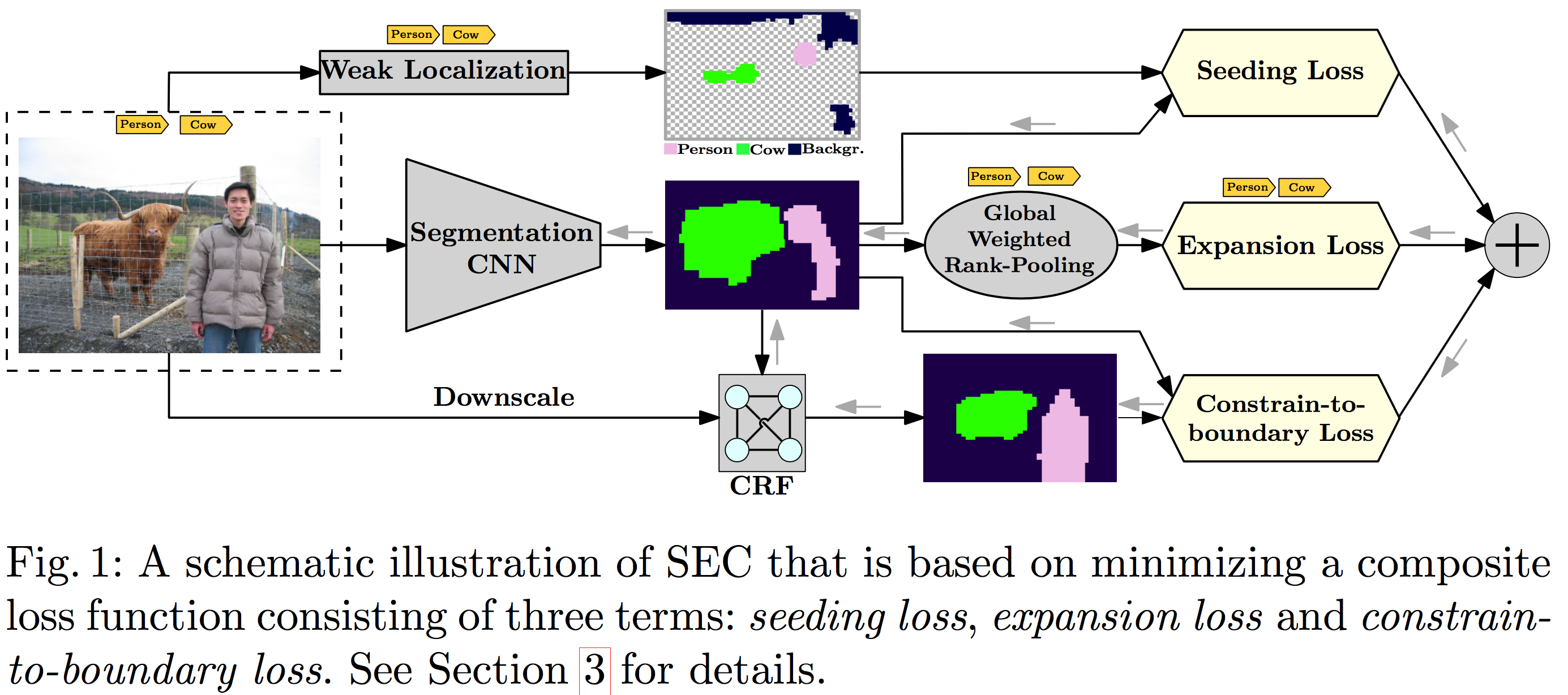
Seeding loss with localization cues
Image-level 的标签本身是不能提供语义目标的定位信息的,但是以 CNN 为基础的 Classification Network 却能够提供一个比较弱的定位信息(weak localization),如下图所示。
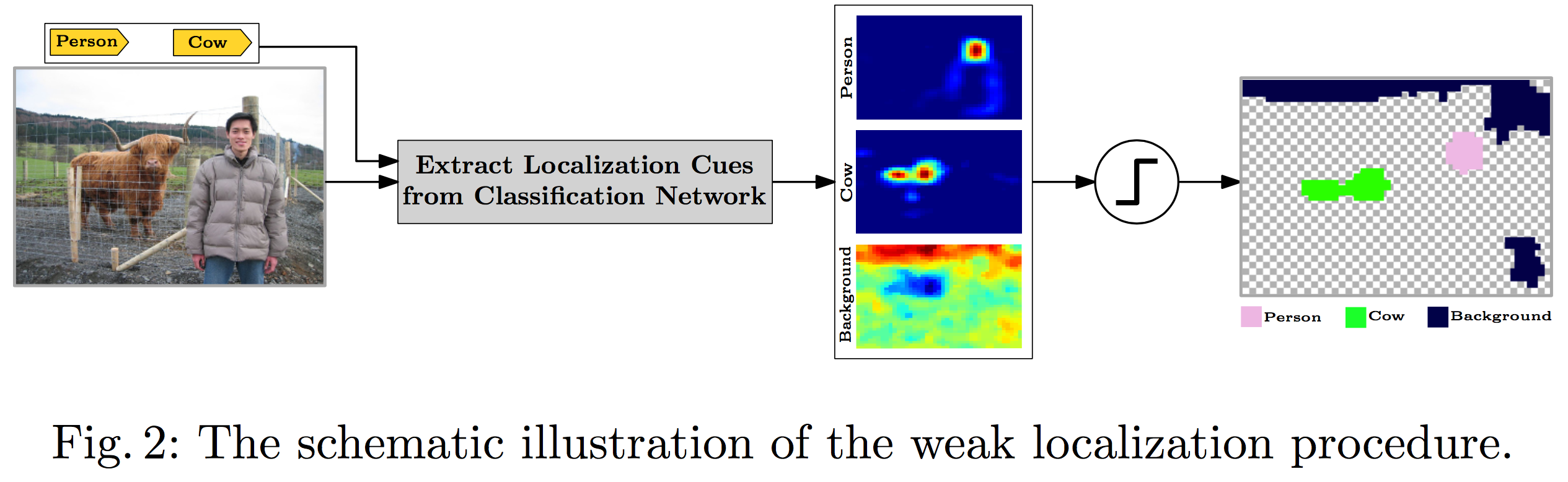
当然,这种 weak location 或者说 location cues 并没有精确到能直接拿来当 full and accurate segmentation masks 的地步。不过还是可以用来指导弱监督分割网络的。文中提到的 seeding loss 主要是用来使得网络只匹配 weak localization 的 landmark,而无视图像中的其他部分。seeding loss $L_{seed}$ 的定义如下: $$ L_{seed}(f(X), T, S_c) = - \frac{1}{\sum_{c\in T} |S_c|} \sum_{c\in T} \sum_{u\in S_c} log f_{u,c}(X) $$ 需要注意的是,文章中的 weak location 是预先计算好的,并非在训练过程中生成。前景用的是 *Learning deep features for discriminative localization*,背景用的是 Deep inside convolutional networks: Visualising image classification models and saliency maps 中的方法
Expansion loss with global weighted rank pooling
要度量分割后的 mask 与原来的 image-level 标签的一致程度的话,可以把每个像素的分割的得分合起来形成一个总的分类得分,然后再套上个 loss function 就能用来训练多标签的图像分类了。一般来说,有两种比较常用的方法:
- 一个是 GMP (global max-pooling),对于一张图像$X$,每个类$c$的得分就是所有像素的该类得分的最大值$max_{u\in {1,\dots,n}} f_{u,c} (X)$。GMP 仅仅鼓励单个位置的响应变得很高,因此常常低估了目标的大小。
- 另外一个就是 GAP (global average-pooling) ,得分是所有像素该类得分的平均值$\frac{1}{n} \sum ^n _{u=1} f_{u,c} (X)$。而 GAP 鼓励所有的响应都变高,因此常常高估了目标的大小。
文中提出了一个叫做 GWRP 的方法,具体来说是这样的:对于一个类$c\in C$,定义其预测得分的一个降序排列$I^c = {i_1, \dots, i_n}$,即$f_{i_1, c} (x) \ge f_{i_2, c} (x) \ge \dots \ge f_{i_n, c} (x)$ 。同时令$d_c$为类别$c$得分的衰减系数。那么 GWRP 的分类得分$G_c(f(X), d_c)$可定义为: $$ G_c (f(X); d_c) = \frac{1}{Z(d_c)} \sum ^n _{j=1} (d_c)^{-1} f_{i_j, c} (X) \text{, where } Z(d_c) = \sum ^n _{j=1} (d_c) ^ {j-1} $$ 值得注意的是,当$d_c = 0$时,GWRP 即为 GMP ($0^0=1$),而当$d_c = 1$时,GWRP 为 GAP。也就是说, GWRP 是前述两种方法的一个泛化形式,通过$d_c$来控制。
原则上来说,可以给每个类和每张图片设置不同的衰减系数$d_c$,不过这就需要知道每个类里面的物体通常的大小这样的先验知识,显然我们用的弱监督是没有这类信息的。因此,文中只设置了三个不同的$d_c$:
- $d_{+}$:在图像中出现了的类别的衰减系数
- $d_{-}$:在图像中未出现的类别的衰减系数
- $d_{bg}$:图像背景类别的衰减系数。
这三个系数的具体取值见第四节。
综上,expansion loss 的完整形式如下: $$ \begin{align} L_{expand}(f(X), T) = &-\frac{1}{|T|} \sum _{c\in T} log G_c (f(X);d_{+}) \\ &-\frac{1}{|C’ \backslash T|} \sum _{c\in C’\backslash T} log G_c (f(X);d_{-}) \\ &- logG_{c^{bg}} (f(X);d_{bg}) \end{align} $$
Constrain-to-boundary loss
使用 constrain-to-boundary loss 的思想是要惩罚网络,使其不要预测出和输入图像的色彩与空间信息不连续的分割。也就是说,要鼓励网络学习到生成与目标边界相匹配的分割 mask。
具体来说,就是构建了一个全连接的 CRF 层,$Q(X,f(X))$,unary potentials 用的是分割网络预测出的对数概率得分,pairwise potentials 则是只取决于图像像素的定值参数形式。为了与分割 mask 的分辨率相匹配,还要对图像 $X$ 降采样。具体的方式见第四节。
总而言之, constrain-to-boundary loss 被定义为网络输出与 CRF 输出之间的 KL 散度: $$ L_{constrain} (X, f(X)) = \frac{1}{n} \sum ^n _{u=1} \sum _{c\in C} Q_{u,c} (X, f(X)) log \frac{Q_{u,c}(X, f(X))}{f_{u,c}(X)} $$ 这一构建形式的公式能够很好地达到预期目标。其能鼓励网络输出与 CRF 的输出接近,而 CRF 的输出又被确信是能够遵循图像边缘的。
Training
既然要训练,那么反向传播肯定是要的,因此各个层都要是可微的。其它层都没什么问题,全连接 CRF 层的梯度计算方法见 Random field model for integration of local informationand global information 。
Experiments
Experiment setup
Dataset and evaluation metric
文中用的数据集是 PASCAL VOC 2012,含背景在内共21个类别。原版的 VOC 2012 的语义分割部分的图像很少,训练集、验证集、测试集分别是1464、1449、1456张图像。所以文章里还用了 SegmentationAug 的扩充数据集,里面总共有10582张弱标注的图像,这个数量基本上够了。
至于与其他方法的对比是在验证集与测试集上进行比较。因为验证集的 ground truth 是向公众开放的,所以主要在验证集上研究一些 SEC 中不同组件之间的相互影响。而测试集必须在 PASCAL VOC 的官方服务器上才能得到结果的,因此就只是用来对比结果。
性能度量用的是最常见的 mIoU。
Segmentation network
本文所选用的分割网络是基于 VGG-16 修改而来的 DeepLab-CRF-LargeFOV,输入为321x321,输出41x41的 mask。除了最后一层预测层初始化为均值为0方差为0.01的正态分布外,其余卷积层都按照 VGG 原本的方式初始化。
Localization network
定位网络也是根据 VGG-16 改的,训练的话是用 SegmentationAug 数据集训练一个多标签分类的问题。详细的方法和参数在文章的附录里面。值得注意的是,在训练的时候,为了提高效率,降低计算复杂度,localization cues是预先生成好的。
Optimization
用的是传统的 batched SGD来训练。总计8000次迭代,batch size为15,dropout rate为0.5,weight decay为0.0005。初始 learning rate 为0.001,每2000次迭代除以10。
硬件设备用的是 TITAN-X,训练一次大约7到8小时。
Decay parameters
经验法则如下:
- 对于那些没有出现在图像中的类别,我们希望预测的像素越少越好。所以说令$d_{-}=0$,即使用GMP。
- 对于那些出现在图像中的类别,建议前10%的得分能够占到总得分之和的50%。对于41x41的mask来说,差不多相当于$d_{+}=0.996$。
- 对于背景类别,建议前30%的得分占到总得分之和的50%,在文中是$d_{bg}=0.999$
Fully-connected CRF at training time
Pairwise parameter 照搬 Efficient inference in fully connected CRFs with gaus- sian edge potentials 这篇文章的默认值,除了把所有的空间距离项乘了12(为了与预测出来的 mask 大小相匹配,文中把原始图像降采样了)。
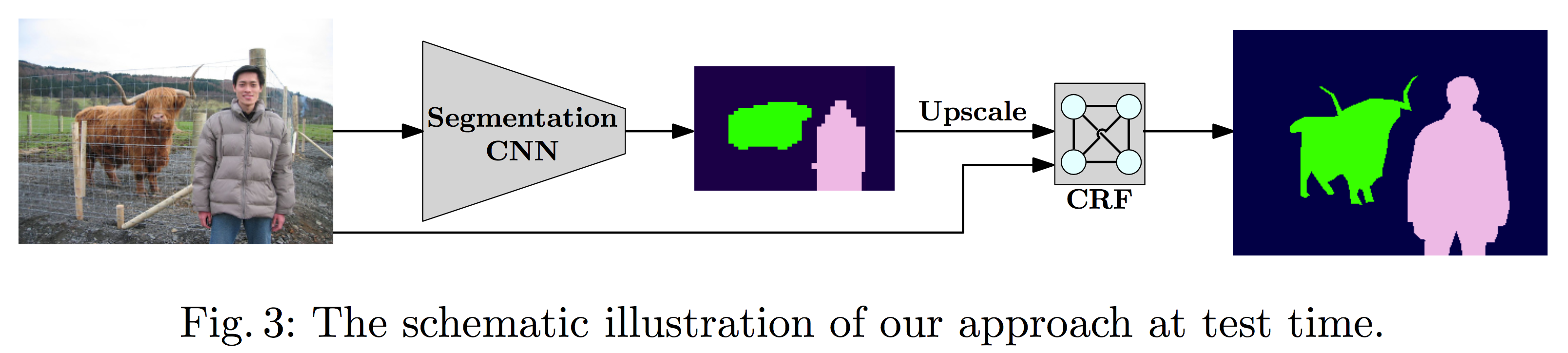
Inference at test time
分割网络最终输出的图像大小比原始图像小,因此还需要经过上采样以及过一遍全连接 CRF 来 refine。
Results
(To be continued)