Notes for Deep Learning: Optimization Algorithms
Contents
This post is an overview of different optimization algorithms for neural networks.
| Optimization Algorithms | Resources |
|---|---|
| RMSProp | [paper] [code] |
| Nesterov | [paper] [code] |
| AdaGrad | [paper] [code] |
| AdaDelta | [paper] [code] |
| Adam/AdaMax | [paper] [code] |
| AMSGrad | [paper] [code] |
| AdamW | [paper] [code] |
| AdamBound | [paper] [code] |
Problem
本篇博文主要讨论基于梯度下降的优化算法。
给定模型参数$\theta \in \mathbb{R}^d$以及目标函数$J(\theta)$,梯度下降方法通过在梯度$\nabla_\theta J(\theta)$ 相反的方向上更新参数$\theta$,来最小化$J(\theta)$。学习率$\eta$则决定了更新的步长。关于为何可以使用梯度下降方法来最小化目标函数,可见此文章,摘录如下:
目标函数的输入为向量,输出为标量。假设目标函数$J: \mathbb{R}^d \rightarrow \mathbb{R}$的输入是一个$d$维向量$\boldsymbol{\theta} = [\theta_1, \theta_2, \ldots, \theta_d]^\top$。目标函数$f(\boldsymbol{\theta})$有关$\boldsymbol{\theta}$的梯度是一个由$d$个偏导数组成的向量:
为表示简洁,我们用$\nabla J(\boldsymbol{\theta})$代替$\nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta})$。梯度中每个偏导数元素$\partial J(\boldsymbol{\theta})/\partial \theta_i$代表着$J$在$\boldsymbol{\theta}$有关输入$\theta_i$的变化率。为了测量$f$沿着单位向量$\boldsymbol{u}$(即$|\boldsymbol{u}|=1$)方向上的变化率,在多元微积分中,我们定义$f$在$\boldsymbol{\theta}$上沿着$\boldsymbol{u}$方向的方向导数为
依据方向导数性质,以上方向导数可以改写为
方向导数$\text{D}_{\boldsymbol{u}} J(\boldsymbol{\theta})$给出了$J$在$\boldsymbol{\theta}$上沿着所有可能方向的变化率。为了最小化$J$,我们希望找到$J$能被降低最快的方向。因此,我们可以通过单位向量$\boldsymbol{u}$来最小化方向导数$\text{D}_{\boldsymbol{u}} J(\boldsymbol{\theta})$。
由于$\text{D}_{\boldsymbol{u}} J(\boldsymbol{\theta}) = |\nabla J(\boldsymbol{\theta})| \cdot |\boldsymbol{u}| \cdot \text{cos} (\varphi) = |\nabla J(\boldsymbol{\theta})| \cdot \text{cos} (\varphi)$, 其中$\varphi$为梯度$\nabla J(\boldsymbol{\theta})$和单位向量$\boldsymbol{u}$之间的夹角,当$\varphi = \pi$时,$\text{cos}(\varphi)$取得最小值$-1$。因此,当$\boldsymbol{u}$在梯度方向$\nabla J(\boldsymbol{\theta})$的相反方向时,方向导数$\text{D}_{\boldsymbol{u}} J(\boldsymbol{\theta})$被最小化。因此,我们可能通过梯度下降算法来不断降低目标函数$J$的值:
同样,其中$\eta$(取正数)称作学习率。这是一个超参数,需要人工设定。
- 如果使用过小的学习率,会导致\theta$$更新缓慢从而需要更多的迭代才能得到较好的解。
- 如果使用过大的学习率,$\left|\nabla J(\boldsymbol{\theta})\right|$可能会过大从而使前面提到的一阶泰勒展开公式不再成立:这时我们无法保证迭代$\boldsymbol{\theta}$会降低$J(\boldsymbol{\theta})$的值。
Gradient Descent and Its Variants
Batch Gradient Descent
朴素的梯度下降方法(又被称为batch gradient descent方法),是在整个训练数据集上,计算目标函数关于参数的梯度$\nabla_\theta J(\theta)$,而后更新参数:
$$ \boldsymbol{\theta} = \boldsymbol{\theta} - \eta \cdot \nabla_\boldsymbol{\theta} J( \boldsymbol{\theta}) $$
其代码实现为:
|
|
也就是说,其遍历一次训练数据集,更新参数的次数为$1$。
其优点在于:
- 一次性在整个数据集上求梯度并更新参数,可以保证其求出的梯度方向至少是局部最优的;
- 对于凸优化问题,可以保证收敛到全局最优;对于非凸问题,可以保证收敛到局部最优。
其缺点在于:
- 每次自变量迭代的计算开销为$\mathcal{O}(n)$,它随着$n$线性增长。因此,当训练数据样本数很大时,梯度下降每次迭代的计算开销很高。而且如果整个训练数据集超过了内存大小,就很难实现这种计算方式;
- 同时,这种优化方式不能够实现在线更新,不能实时添加新的样本。
Stochastic Gradient Descent
随机梯度下降方法(stochastic gradient descent, SGD)相对于batch gradient descent方法,主要在于其每次求梯度并更新参数时,只使用一个训练样本: $$ \boldsymbol{\theta} = \boldsymbol{\theta} - \eta \cdot \nabla_\boldsymbol{\theta} J( \boldsymbol{\theta}; \boldsymbol{x}^{(i)}; \boldsymbol{y}^{(i)}) $$ 其代码实现为:
|
|
其优点在于:
- 相比于batch gradient descent,由于其每次更新参数只用一个训练样本,所以更新速度快,可以在线学习
- 随机梯度
$\nabla J_i(\boldsymbol{\theta})$是对梯度$\nabla J(\boldsymbol{\theta})$的无偏估计:$E_i \nabla J_i(\boldsymbol{\theta}) = \frac{1}{n} \sum_{i = 1}^n \nabla J_i(\boldsymbol{\theta}) = \nabla J(\boldsymbol{\theta})$。这意味着,平均来说,随机梯度是对梯度的一个良好的估计。
其缺点在于:
- 减少了每次迭代的计算开销,每次迭代的计算开销从GD的$\mathcal{O}(n)$降到了常数$\mathcal{O}(1)$。
- 其引入的噪声大,会使得目标函数大幅波动
- 每次更新不能保证向局部最优收敛,很容易超调,收敛困难
Mini-batch Gradient Descent
Mini-batch Gradient Descent方法结合了上述两种方法的优点,其每次随机均匀采样一个小批量的训练样本来计算梯度并更新参数: $$ \boldsymbol{\theta} = \boldsymbol{\theta} - \eta \cdot \nabla_\boldsymbol{\theta} J( \boldsymbol{\theta}; \boldsymbol{x}^{(i:i+B)}; \boldsymbol{y}^{(i:i+B)}) $$ 其代码实现为:
|
|
- $|\mathcal{B}|$代表批量大小,即小批量中样本的个数,为一超参数,主要根据模型大小以及显存大小决定。
- 基于随机采样得到的梯度的方差在迭代过程中无法减小,因此在实际中,(小批量)随机梯度下降的学习率可以在迭代过程中自我衰减,例如
$\eta_t=\eta t^\alpha$(通常$\alpha=-1$或者$-0.5$)、$\eta_t = \eta \alpha^t$(如$\alpha=0.95$)或者每迭代若干次后将学习率衰减一次。如此一来,学习率和(小批量)随机梯度乘积的方差会减小。而梯度下降在迭代过程中一直使用目标函数的真实梯度,无须自我衰减学习率。 - 小批量随机梯度下降中每次迭代的计算开销为
$\mathcal{O}(|\mathcal{B}|)$。当批量大小为$1$时,该算法即为随机梯度下降;当批量大小等于训练数据样本数时,该算法即为梯度下降。其在每个迭代周期的耗时介于梯度下降和随机梯度下降的耗时之间。
其优点在于:
- 相比于SGD,减少了训练过程中参数更新的方差,使得训练过程更加稳定;
- 相比于GD,由于只使用了部分训练样本,使得训练速度得以提升。
Drawbacks
上述三种梯度下降的方法虽然能用,但是还有一些缺陷没能解决:
- 合适的学习率问题。学习率太小会使得收敛过慢,太高则会使模型难以收敛,甚至发散;
- 学习率的调整问题。现有的学习率调整方法(linear annealing或者step annealing等)都需要事先定义好,在训练过程中难以根据训练数据的特性来调整;
- 避开或者跳出大量局部最小值或者鞍点的问题。
Local Optima & Saddle Point
假设一个函数的输入为$k$维向量,输出为标量,那么它的海森矩阵(Hessian matrix)有$k$个特征值。
其中二阶偏导数
该函数在梯度为$0$的位置上可能是局部最小值、局部最大值或者鞍点。
- 当函数的海森矩阵在梯度为零的位置上的特征值全为正时,该函数得到局部最小值。
- 当函数的海森矩阵在梯度为零的位置上的特征值全为负时,该函数得到局部最大值。
- 当函数的海森矩阵在梯度为零的位置上的特征值有正有负时,该函数得到鞍点,其在某些方向上取得局部最小值,在另外的方向上取得局部最大值。
随机矩阵理论告诉我们,对于一个大的高斯随机矩阵来说,任一特征值是正或者是负的概率都是$0.5$。那么,以上第一种情况的概率为$0.5^k$。由于深度学习模型参数通常都是高维的($k$很大),目标函数的鞍点通常比局部最小值更常见。
Gradient Descent Optimization Algorithms
为了解决原始的梯度下降方法的不足,研究者们又提出了新的改进算法。
Momentum
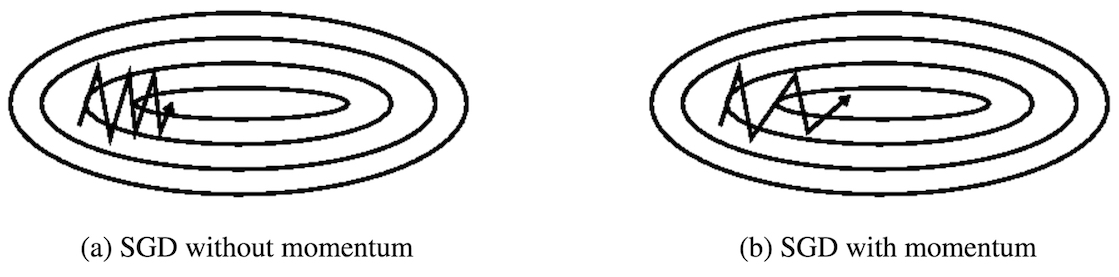
Momentum方法与SGD比较 (Source: Sebastian Ruder’s blog post)
设时间步$t$的自变量为$\boldsymbol{\theta}_t$,梯度为$\boldsymbol{g}_t = \nabla J(\boldsymbol{\theta})$,学习率为$\eta_t$。 在时间步$0$,动量法创建速度变量$\boldsymbol{v}_0$,并将其元素初始化成$0$。在时间步$t>0$,动量法对每次迭代的步骤做如下修改:
其中,动量超参数$\gamma$满足$0 \leq \gamma < 1$。当$\gamma=0$时,动量法等价于Mini-batch SGD。
通俗地理解,使用动量之后,梯度下降的方向更加倾向于在过往的历次梯度方向中都具有比较大的梯度值的方向。如上图所示,所有梯度在水平方向上为正(向右),而在竖直方向上时正(向上)时负(向下)。动量法的使用,能够减少梯度方向的振荡,并且能够下降到更加相关的方向。
Exponentially Weighted Moving Average
为了从数学上理解动量法,让我们先解释一下指数加权移动平均(exponentially weighted moving average)。给定超参数$0 \leq \gamma < 1$,当前时间步$t$的变量$y_t$是上一时间步$t-1$的变量$y_{t-1}$和当前时间步另一变量$x_t$的线性组合:
我们可以对$y_t$展开:
令$n = 1/(1-\gamma)$,那么$\left(1-1/n\right)^n = \gamma^{1/(1-\gamma)}$。因为
所以当$\gamma \rightarrow 1$时,$\gamma^{1/(1-\gamma)}=\exp(-1)$,如$0.95^{20} \approx \exp(-1)$。如果把$\exp(-1)$当作一个比较小的数,我们可以在近似中忽略所有含$\gamma^{1/(1-\gamma)}$和比$\gamma^{1/(1-\gamma)}$更高阶的系数的项。例如,当$\gamma=0.95$时,
因此,在实际中,我们常常将$y_t$看作是对最近$1/(1-\gamma)$个时间步的$x_t$值的加权平均。例如,当$\gamma = 0.95$时,$y_t$可以被看作对最近20个时间步的$x_t$值的加权平均;当$\gamma = 0.9$时,$y_t$可以看作是对最近10个时间步的$x_t$值的加权平均。而且,离当前时间步$t$越近的$x_t$值获得的权重越大(越接近1)。
Momentum in EMA
现在,我们对动量法的速度变量做变形:
由指数加权移动平均的形式可得,速度变量$\boldsymbol{v}t$实际上对序列${\eta{t-i}\boldsymbol{g}_{t-i} /(1-\gamma):i=0,\ldots,1/(1-\gamma)-1}$做了指数加权移动平均。换句话说,相比于小批量随机梯度下降,动量法在每个时间步的自变量更新量近似于将前者对应的最近$1/(1-\gamma)$个时间步的更新量做了指数加权移动平均后再除以$1-\gamma$。所以,在动量法中,自变量在各个方向上的移动幅度不仅取决当前梯度,还取决于过去的各个梯度在各个方向上是否一致。也就是说,动量法依赖指数加权移动平均使得自变量的更新方向更加一致,从而降低发散的可能。
Momentum的最终速度是Mini-batch SGD的$1/(1-\gamma)$倍。
Nesterov

Nesterov方法与Momentum比较 (Source: Sebastian Ruder’s blog post)
Nesterov相当于在动量法的基础上增加了对于二阶梯度的近似,作为一个校正项,这使得优化的收敛速度更为加快。
Adagrad
AdaGrad算法是针对Mini-batch SGD的改进,根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。
例如,当
$\theta_1$和$\theta_2$的梯度值有较大差别时,之前介绍的优化算法,对于参数重的每一个元素,在相同时间步都使用同一个学习率来自我迭代。这时,我们需要选择足够小的学习率使得自变量在梯度值较大的维度上不发散,但这样又会导致自变量在梯度值较小的维度上迭代过慢。
AdaGrad算法会使用一个小批量随机梯度$\boldsymbol{g}_t$按元素平方的累加变量$\boldsymbol{s}_t$。在时间步0,AdaGrad将$\boldsymbol{s}_0$中每个元素初始化为0。在时间步$t$,首先将小批量随机梯度$\boldsymbol{g}_t$按元素平方后累加到变量$\boldsymbol{s}_t$:
其中$\odot$是按元素相乘。接着,我们将目标函数自变量中每个元素的学习率通过按元素运算重新调整一下:
其中$\eta$是学习率,$\epsilon$是为了维持数值稳定性而添加的常数,如$10^{-6}$。这里开方、除法和乘法的运算都是按元素运算的。这些按元素运算使得目标函数自变量中每个元素都分别拥有自己的学习率。
其优点在于,AdaGrad算法在迭代过程中不断调整学习率,并让目标函数自变量中每个元素都分别拥有自己的学习率。小批量随机梯度按元素平方的累加变量$\boldsymbol{s}_t$出现在学习率的分母项中。因此,如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快;反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢。
其缺点在于,由于$\boldsymbol{s}_t$一直在累加按元素平方的梯度,自变量中每个元素的学习率在迭代过程中一直在降低(或不变)。所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。
RMSprop
为了解决AdaGrad在迭代后期学习率过小导致难以找到合适的解的问题,RMSProp将AdaGrad中的梯度平方的累加和换成了梯度平方的指数移动加权平均:
其中$\eta$是学习率,$\epsilon$是为了维持数值稳定性而添加的常数,如$10^{-6}$。因为RMSProp算法的状态变量$\boldsymbol{s}_t$是对平方项$\boldsymbol{g}_t \odot \boldsymbol{g}_t$的指数加权移动平均,所以可以看作是最近$1/(1-\gamma)$个时间步的小批量随机梯度平方项的加权平均。如此一来,自变量每个元素的学习率在迭代过程中就不再一直降低(或不变)。
AdaDelta
同样为了解决AdaGrad在迭代后期学习率过小导致难以找到合适的解的问题,AdaDelta方法在RMSProp使用梯度平方的移动加权平均替代梯度平方累加和的基础上,还使用参数变化量平方的指数移动加权平均$\sqrt{\Delta\boldsymbol{\theta}_{t-1}}$来替代超参数$\eta$。
其中$\epsilon$是为了维持数值稳定性而添加的常数,如$10^{-5}$。当$t=0$时,$\boldsymbol{s}_t$与$\sqrt{\Delta\boldsymbol{\theta}_{t-1}}$均被初始化为$0$。
Adam
Adam算法可以视为是RMSProp算法与动量法的结合,其在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均。也就是说,Adam算法使用了动量变量$\boldsymbol{v}_t$和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量$\boldsymbol{s}_t$,并在时间步$t=0$将它们中每个元素初始化为$0$。
同动量法中一样,给定超参数$0 \leq \beta_1 < 1$(算法作者建议设为$0.9$),时间步$t$的动量变量$\boldsymbol{v}_t$即小批量随机梯度$\boldsymbol{g}_t$的指数加权移动平均:
和RMSProp算法中一样,给定超参数$0 \leq \beta_2 < 1$(算法作者建议设为$0.999$), 将小批量随机梯度按元素平方后的项$\boldsymbol{g}_t \odot \boldsymbol{g}_t$做指数加权移动平均得到$\boldsymbol{s}_t$:
由于我们将$\boldsymbol{v}_0$和$\boldsymbol{s}_0$中的元素都初始化为$0$, 在时间步$t$我们得到$\boldsymbol{v}t = (1-\beta_1) \sum{i=1}^t \beta_1^{t-i} \boldsymbol{g}i$。将过去各时间步小批量随机梯度的权值相加,得到 $(1-\beta_1) \sum{i=1}^t \beta_1^{t-i} = 1 - \beta_1^t$。需要注意的是,当$t$较小时,过去各时间步小批量随机梯度权值之和会较小。例如,当$\beta_1 = 0.9$时,$\boldsymbol{v}_1 = 0.1\boldsymbol{g}_1$。为了消除这样的影响,对于任意时间步$t$,我们可以将$\boldsymbol{v}_t$再除以$1 - \beta_1^t$,从而使过去各时间步小批量随机梯度权值之和为$1$。这也叫作偏差修正。在Adam算法中,我们对变量$\boldsymbol{v}_t$和$\boldsymbol{s}_t$均作偏差修正:
接下来,Adam算法使用以上偏差修正后的变量$\hat{\boldsymbol{v}}_t$和$\hat{\boldsymbol{s}}_t$,将模型参数中每个元素的学习率通过按元素运算重新调整:
其中$\eta$是学习率,$\epsilon$是为了维持数值稳定性而添加的常数,如$10^{-8}$。和AdaGrad算法及其衍生算法(RMSProp算法以及AdaDelta算法)一样,目标函数自变量中每个元素都分别拥有自己的学习率。最后,使用$\boldsymbol{g}_t’$迭代自变量:
AdaMax
Adam中的梯度平方的指数移动加权平均项,可以看作是对梯度的$L_2$正则的指数移动加权平均项。推而广之,可以写作$L_p$正则的形式:
AdaMax就是使用了$L_\infty$正则化的梯度的Adam算法:
- AdaMax相对于Adam的优点主要在于优化稀疏的参数的场景中(例如Word Embedding)。当
$|\boldsymbol{g}_t|$足够小时,由于$\max$函数的作用,其会被完全忽略。这意味着速度$\boldsymbol{s}_t$受到小梯度的影响较少,因此对于梯度的噪声较为鲁棒。- 同时,由于
$\boldsymbol{s}_t$取决于$\max$操作,其初始值不宜为$0$,所以此时不需要像Adam那样,对变量$\boldsymbol{s}_t$作偏差修正。
NAdam
相比于Adam结合了Momentum与RMSProp,NAdam将Neserov与RMSProp方法结合起来。
Neserov方法可以改写为以下形式:
则NAdam可以表示为: