Notes for Adversarial Discriminative Domain Adaptation
Contents
About this paper
- Title: Adversarial Discriminative Domain Adaptation
- Authors: Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell
- Topic: Domain Adaptation
- From: arXiv:1702.05464, appearing in CVPR 2017
Contributions
- 将之前的论文里提到的一些方法,例如weight sharing、base models、adversarial loss等,归入了统一的框架之中,并进行了测试;
- 提出了一种新的框架ADDA,主要思想是不做分类器的自适应,而是设法将目标域的数据映射到域源域差不多的特征空间上,这样就能够复用源域的分类器。
Methods
Generalized architecture for adversarial domain adaptation
如下图所示,文中提出的用于对抗性领域迁移的统一框架,主要是其中有三个可以做选择的地方:
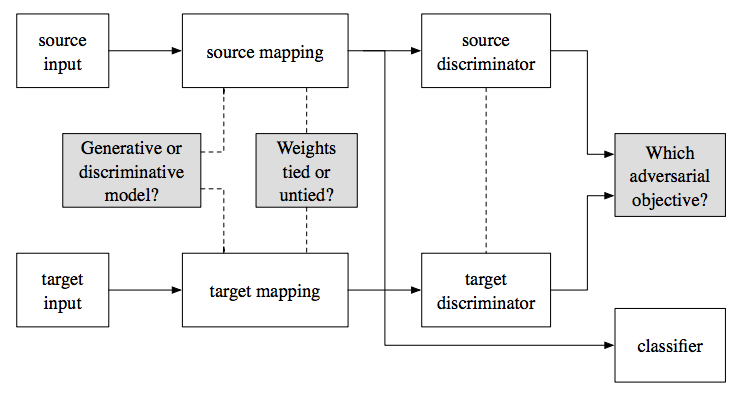
对于源映射(source mapping)与目标映射(target mapping)采用何种参数化的模型的选择。具体地说,是用判别式模型还是生成式模型。早期的领域自适应的方法基本上就是做判别模型的自适应。但是随着GANs兴起,有研究者开始用GANs的生成器通过随机噪声生成采样,然后用判别器中间层的特征作为分类器的输入特征,来训练特定任务的分类器。
对于目标映射参数初始化与参数约束的选择。一般来说都是用源映射的参数来初始化,但是在后续训练中如何约束两者之间参数的关系,使得在映射后两个域的数据之间距离能尽可能的小,这就见仁见智了。
- 一个常见的约束方法是期望两者逐层的参数相等,在CNN上可以用weight sharing来实现。这种对称的变换能减少模型中的参数数量,并且保证至少在源域上,目标映射是可判别的。不过也有坏处,如此一来一个映射需要能工作在两个独立的域上,这可能会在优化过程中导致病态条件(poorly conditioned)。
- 另外一个常见的约束方法是万事不管,根本不约束。
- 此外,还有种非对称变换的方法,只对某些层的参数施加约束。
对抗学习损失函数的选择。文中列举了三种不同的损失函数:
第一个是直接取判别器的相反数,这一点在GAN论文中提到过,会导致判别器收敛已经收敛时生成器梯度消失的问题,因此不予选用。 $$ \mathcal{L} _{adv _ M} = - \mathcal{L} _{adv _ D} $$
第二个是采用GAN论文中的非饱和的损失函数,采用判别器误判的期望来作为损失函数。 $$ \mathcal{L} _{adv _M} (X_s, X_t, D) = - \mathbb{E} _{x_t,\sim X_t} [\log D(M_t (x_t))] $$
第三个则是作者在前一篇文章中提出来的domain confusion loss: $$ \mathcal{L} _{adv _M} (X_s, X_t, D) = - \sum _{d\in {s, t}} \mathbb{E} _{x_d \sim X_d} \left[ \frac{1}{2} \log D (M_d (x_d)) + \frac{1}{2} \log (1 - D (M_d (x_d))) \right] $$
ADDA architecture
对于上述统一框架中,ADDA的选择如下:
- 首先,ADDA选择了使用判别模型,因为作者觉得用生成模型生成领域内的样本所训练出来的参数,很大一部分对于判别器的自适应任务来说并没有什么用。另外,之前的文章有很多是直接在判别的空间上做自适应,这对于两个很相似的域来说是可以的(比如MNIST与USPS),但是对于一些不那么相似的域之间(比如MNIST与SVHN),也就是所谓的“困难任务”上,这么做就不一定能够收敛了。
- 其次,对于源映射域目标映射,ADDA选择不对两者的参数关系作出约束。当然,为了让目标映射快速收敛起见,ADDA使用了源映射的参数来初始化目标映射模型。
- 最后,ADDA使用了非饱和的GANs损失函数。
如下图所示,整个ADDA的工作流程可以分为三个步骤:
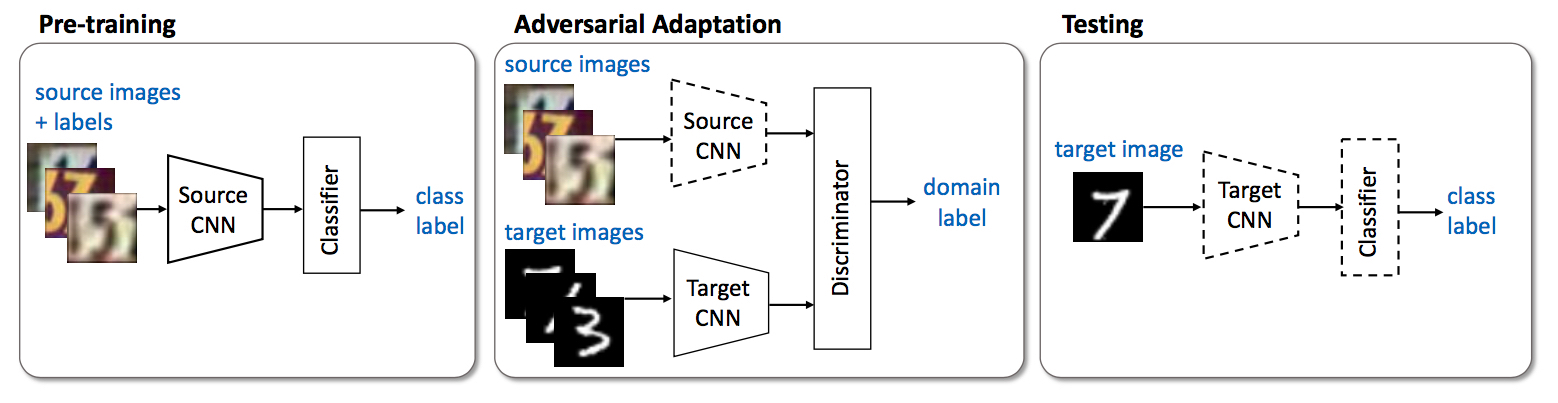
- 首先,使用带标记的源数据$(X_s, Y_s)$来训练源映射$M_s$与分类器$C$,优化$\mathcal{L}_{cls}$;
- 其次,固定$M_s$,使用GANs来训练$M_t$,优化$\mathcal{L}_{adv_D}$与$\mathcal{L}_{adv_M}$;
- 最后,使用$M_t$,将目标域的数据变换到特征空间,并交由分类器$C$来分类。